



Closing the air-gap: Advancing flexibility in analytic pipelines

From IC Insider Red Hat
Adopting an OSINT model, including the extended version, offers ways to extend and utilize commercial analytic capabilities, albeit with limitations. Ideally, leveraging commercial capabilities without these constraints would allow the Intelligence Community (IC) to effectively tailor data processing and analytics to their missions.
Moving organic analytic tools outside the air-gap is currently risky. New technologies like confidential computing and AI/ML play a crucial role in enabling the IC to regain control over analytic processes previously restricted by air-gapped environments. Fundamentally, leveraging OSINT and existing commercial analytics tools goal is pushing traditionally air-gapped analytics into untrusted domains and relying on these new technologies to protect these analytics from being easily compromised.
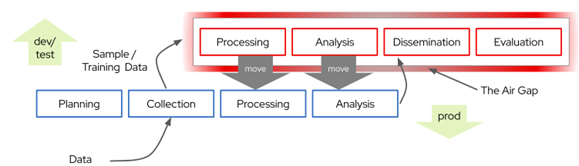
Figure 1: If we could safely move production analytic tools outside the air-gap, we could leverage the economies, scale, and reach of commercial infrastructure providers.
When synthesized with the current air gapping method, several crucial approaches and technologies significantly enhance operational security objectives, such as:
Declarative systems
Declarative approaches allow us to state our intentions of how a system should behave – automation realizes these intentions. Directed at the broad domain of data management, we can apply declarative approaches to separate roles and functions, enforce discrete and differential access controls, lower insider risks, or remove human errors. Declarative IT is usually though of as a system administration or DevOps tool. Increasing use and adoption of declarative approaches for data science and machine learning operations (or MLOps) is opportunity to acquire these same advantages for analytics processes.
Figure 2: A data pipeline (image from Apache Nifi)
Fortunately, the focus of data model engineering today is on precisely this declarative approach – seen in tool emergence. For example, Apache NiFi and Airflow or Kubeflow’s Data Pipelines – define abstract ‘data pipelines’ and ‘model pipelines’, as fundamental tools for the composition of the associated systems. Using these, data scientists can define, test, and refine their data management and ETL workflows against test data in isolated or clean room enclaves. When ready, encoded and parameterized controlled artifacts are handed these off to others for further refinement, deployment to other domains, or forking and reuse by others. The data and the analytical products are decoupled, remain in their domain, and don’t need to travel with the data or model itself.
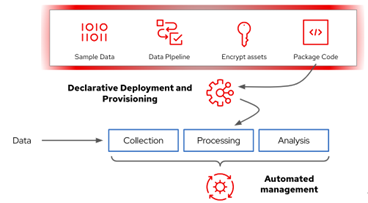
Figure 3: Using declarative pipelines for cross-domain analytic workflows
Effectively using a declarative approach where information protections are paramount requires automation and strong governance. We expect the system to behave as our automation dictates or fail in environments we don’t control.
Confidential computing
Protect a workload from its surrounding infrastructure (and vice versa) with emerging technologies that provide confidentiality assurances for our workloads. While a rapidly developing area, it’s accessible today in commodity IT depending on our needs and goals. Fundamentally, all of these use hardware-assisted means like trusted execution environments (TEEs) to create enclaves with strengthened security postures. Sensitive data and computations from unauthorized access are protected, even by privileged software or administrators, encrypting data and processes while in use.
In particular, confidential containers, as embodied by the CNCF Confidential Containers (CoCo) project, employ cloud-native platforms for confidential computing technologies. Many data and machine learning declarative pipeline approaches use containers as the primary means to orchestrate their pipelined activities, gaining enormous mutual synergies.
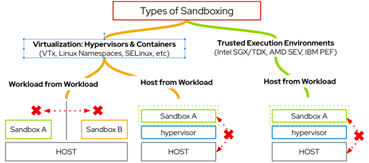
Figure 4: How we can protect workloads using confidential computing
Confidential containers and TEEs extend the protections provided by basic virtualization through built-in encryption, keeping our data pipeline execution or AI/ML models protected until loaded by the hardware TEE for use. Relying on encryption and virtualization technologies today for many multi-domain protections, one primary concern is establishing the authenticity and integrity of the software, data, and other components using Zero Trust Architectures and careful design and planning of our roots of trust and attestations.
Virtualization
Virtualization underpins a lot of approaches to protecting data in multi-domain and cross-domain applications. Confidential containers are the next evolution, but virtualization already enjoys near-ubiquitous hardware support and is used to create trusted security boundaries. It is a fundamental technology and, indeed, is used to implement confidential computing environments today where the platform itself can be trusted. Fortunately, this is the case for many environments where physical access and security are robust or the compute platform is managed, governed, and protected from tampering via automated declarative processes. Trusted cloud service providers are examples of where sufficient guarantees may be available. We can use hardware, software, and platform attestations to assert some assurances that we are operating on platforms that can be trusted in these fashions.
AI/ML
The properties of AI/ML models that make them challenging to trust can also aid in providing additional protections as we move analytics into other domains: AI/ML should be the analytic approach of choice for this reason. First and foremost, AI/ML models inherently obfuscate the data contained within and the details of the flow of information within the models themselves. Still, inherent obfuscation must be tested and validated within the development and test environments to examine and probe for information leakage from the model. Tailored training incorporated into the declarative data and machine learning pipelines using automation and declarative policies validates their use when deployed to production.
AI/ML models must also be attached to various other objects, such as object or data embedding maps, and metadata to make them useful, and this is an opportunity to mutate or shard the models and add additional obfuscation. Sharding a model and separating key subparts (eg, a layer in a NN, a weight vector, shape, or other metadata parameters) lowers risk of compromise and impact if compromised. Layered declarative workflow constructs and confidential computing environments can further support this process of obfuscation and reconstruction. Confidential computing for AI/ML models, often a critical point of tradecraft, is also an excellent example of how we can protect these specific workloads using this technology.
Attestations, Blockchains, and distributed transactions
Regardless of the mix of tools discussed here, implementations all rely on the capability assertions and assurances provided by involved components. Confidential computing, whether via Kata containers or podman/libkrun relies on examining and validating the attestations provided. Complex provisioning and orchestration requires specialized platform components – attestations of the platform itself, anchored by hardware roots of trust anchored in the hardware. For example, keys and certificates must be loaded into the bootstrap process, the platform attestations verified, and the TEE initialized with the user data – for each use in a data analytics or model pipeline.
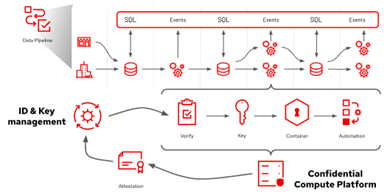
Figure 5: Managing attestation and the supporting keys and certificates in a confidential computing environment; extending this to data and model pipelines will require governance over distributed execution contexts and trust models
Today, PKI and traditional cryptographic signing and certificates are the model: critical assets we must control and protect carefully. As pipeline automation is applied for the critical management processes here, trust passes up and cannot be pre-built into the confidential computing paradigm. But hardware trust provided by Secure Boot, augmented with Policy-Based Decryption such as Network-Bound Disk Encryption, aids in this process. But future tools based on transparency logs like Google’s Trillian or SigStore may provide ways to distribute the trust process.
By embracing these technologies and approaches, the IC can achieve economies of scale, enhanced access, and improved security without compromising operational objectives. This strategic integration of advanced technologies mitigates risks associated with moving analytic processes outside air-gapped environments and enables organizations to realize their operational goals effectively and securely.
About IC Insiders
IC Insiders is a special sponsored feature that provides deep-dive analysis, interviews with IC leaders, perspective from industry experts, and more. Learn how your company can become an IC Insider.



