



A Gentle Introduction to Retrieval Augmented Generation (RAG) for the Intelligence Community

From IC Insider Clarifai
By Douglas Shapiro, Clarifai
Imagine an intelligence analyst, Alice, who focuses on measuring the Chinese economy. She is building a bottoms-up analysis of economic strength based on quarterly announcements of several local municipalities’ projections. She knows the party’s estimates are overly optimistic, but by how much? What were the sentiments of the adjectives used in the latest economic announcement? And were they stronger or weaker than one, four, or twenty quarters ago? Based on historical results, does the municipality systematically overstate growth by a predictable amount? Determining key indicators like growth and derivative metrics like tax revenue can act as building blocks and proxies for defense spending, capacity building, and ultimately projecting military power.
Alice can use a language model (LLM) to assist with this exercise. A large language model is a type of artificial intelligence program that can recognize and generate text. LLMs use machine learning or “training” on huge sets of data and a type of neural network architecture called a transformer model to try to “understand” the data. Mathematically, LLMs embed textual, and other unstructured information, like pictures and videos, into a lower-dimensional vector representation. Put extremely simply, LLMs are refined next-word predictors. (Technically, they’re the next token predictors.) The magic trick is when presented with a question – the LLMs will try to predict the answer as the next sequence of words. Thus, Alice could ask the LLM whether economic variables are trending positively or negatively, or whether the announcement language has softened or hardened over time. Soon a nuanced picture may emerge, perhaps growth is decelerating based on real estate or demographic factors, or growth may be surging based on additional infrastructure investment.
However, most LLMs will not natively contain quarterly announcements of local Chinese statistics directly in their model training data. Especially newer announcements that were just recently released. Some LLMs will not contain Mandarin language training data at all, let alone niche news that’s not of general interest. Thus LLMs can suffer from generating incorrect information or relying on outdated knowledge. When you prompt an LLM about topics it has not been specifically trained on, it may decline to respond or hallucinate. Retrieval-Augmented Generation (RAG) is now a well-established and rapidly evolving technique to address these challenges. RAG incorporates external knowledge bases into the model’s generative process, thereby enhancing the models’ accuracy, credibility, and overall functionality. So RAG addresses two large problems with LLMs, gaps in knowledge and outdated knowledge.
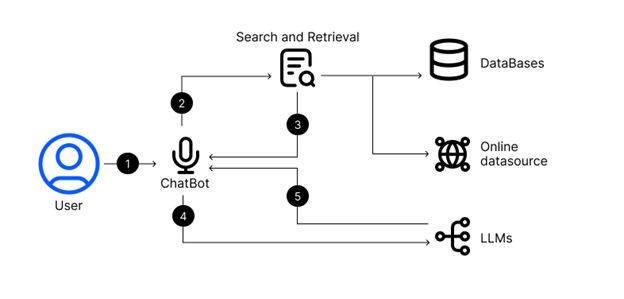
Figure 1: An example of how a RAG system can work with LLMs.
RAG combines the generative capabilities of LLMs with real-time information retrieval from external sources. When a query is made, RAG retrieves relevant and current information from an external corpus. To date, in practice, the external information has usually been text documents, but there is no technical barrier for the retrieval to be a different form factor like graphics, pictures, or videos. The external corpus could also be proprietary data that never leaves an on-premises installation, meaning public models could be used with classified data. By adding more information to Alice’s prompt, a more contextual and accurate response is provided. RAG is an effective method for enhancing LLMs due to its ability to integrate real-time, external information, addressing the inherent limitations of static training datasets. So, when a local government makes a new economic announcement if you’ve set up a way to track this news properly, RAG could let you instantly incorporate that new information with your queries. RAG is also a more computationally efficient approach than continuously retraining models, as it dynamically retrieves information as needed.
RAG techniques are becoming more advanced. ‘Naive RAG ‘, already described, takes a basic corpus of text documents, where texts are chunked, vectorized, and indexed to create prompts for LLMs. ‘Advanced’ RAG is like Naive plus. It combines pre-retrieval and post-retrieval strategies with sophisticated architectures like query rewriting, chunk reranking, and prompt summarization. ‘Modular’ RAG takes all this to the next level with various iterative approaches. For most applications, including Alice’s economic analysis, Naive RAG is likely to be performant and sufficient.
With just Naive RAG, Alice can start to triangulate nationwide economic pronouncements and highly visible geopolitical events (information possibly contained in the base LLM) along with economic historical announcements that occur at the municipality level (RAG from a separate compilation of text and/or databases). She can start building an intuition on the overall strength of the Chinese economy. A plethora of additional intelligence applications are easy to conjure up: diplomats can track multi-lateral positions in negotiations in real-time, data can be analyzed for threats, even wargaming simulations could occur based solely on diverse experts’ opinions.
Understandably, there is still some reticence in the intelligence community for misuse of LLMs. But the original technical limitations continue to be overcome, not just by retrieval-augmented generation. Recent advances in programmatic prompt optimization, longer context windows, and tricks to improve latency mean LLMs are rapidly getting better and faster. Despite these tool improvements, proliferation will inevitably lead to some misapplications. There are risks in over adoption, the tool isn’t right for every job. The cost of producing new analytic content is essentially zero, so intelligence analysis that regurgitates existing conventional wisdom is likely to amplify the median or modal point of view and reinforce groupthink. Another risk includes a reinforced inability by analysts to imagine black-swan-like intelligence events. Conversely, strategic hallucination, or intentionally increasing the temperature of models may be able to seed our imagination to consider points of view that are outside of the mainstream. Furthermore, overconfidence in ‘insights’ derived from LLMs may make it harder for people to think creatively.
Regardless of these risks, with the consolidation of procurement platforms focused on AI projects and new programs to attract talent, the DoD has indicated an appetite to adopt this technology in earnest relative to last year. The LLM adoption barriers the intelligence community faces are primarily no longer technical, but rather bureaucratic, industrial-organizational, and change management-based. Organizations should be shifting from asking themselves not whether it’s technically feasible to use these tools, but rather where they may be able to derive benefits from doing so.
As LLMs assisted with RAG become more entwined with fundamental search engines, the way we obtain and process information, both as an employee and consumer, will soon change. Just as the mantra of the big data era was garbage in leads to garbage out, now garbage in training data (or external corpus of data) will lead to generative garbage out. If the economic pronouncements that Alice tracks are fundamentally lies, disconnected from reality in an unsystematic way, no amount of tinkering with LLMs and RAG will make her job easier. Nonetheless, technical advances in RAG are supercharging the capabilities of LLMs by addressing knowledge gaps and outdated knowledge. Further improvements in multi-modal applications suggest generative AI will continue to play a crucial role not just with everyday applications but with mission critical applications for the intelligence community.
Contact us to learn more about how Clarifai has been providing AI solutions for the US government for the last eight years.
About Clarifai
Clarifai simplifies how developers and teams create, share, and run AI at scale by providing companies with a cutting-edge platform to build enterprise AI faster, leveraging today’s modern AI technologies like Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), data labeling, inference, and more. Founded in 2013, Clarifai is available in cloud, on-premise, or hybrid environments and has been used to build more than one million AI models with more than 380,000 users in 170 countries. Learn more at www.clarifai.com.
About IC Insiders
IC Insiders is a special sponsored feature that provides deep-dive analysis, interviews with IC leaders, perspective from industry experts, and more. Learn how your company can become an IC Insider.



