



Postgres Powered by Iceberg: Zero ETL and Powerful Analytics with Crunchy Data Warehouse

From IC Insider Crunchy Data
By Elizabeth Christensen
PostgreSQL is the bedrock on which many of today’s organizations are built. The versatility, reliability, performance, and extensibility of PostgreSQL make it the perfect tool for operational workloads. The one area in which PostgreSQL has historically been lacking is analytical workloads that query, summarize, filter, and transform large amounts of data.
Modern analytical databases are designed to query data in data lakes in formats like Parquet using a fast vectorized query engine. Data is stored in open table formats such as Apache Iceberg which supports transactions while also offering cheap, infinite, durable storage that object stores like S3 provide. Multiple applications can access data directly from storage in a scalable way without losing data consistency or integrity. If only you could have all that in PostgreSQL.
Crunchy Data recently announced Crunchy Data Warehouse, a modern, high-performance analytics database built into PostgreSQL.
What is Crunchy Data Warehouse?
Crunchy Data Warehouse brings many ground-breaking new features into PostgreSQL:
- Iceberg tables in PostgreSQL: Create, manage, and query Iceberg tables that are cheaply and durably stored in S3. Fast analytical queries span across your operational tables and data lake.
- High performance analytics: Crunchy Data Warehouse extends the PostgreSQL query planner to delegate part of the query to DuckDB for vectorized execution and automatically cache files on local NVMe drives. Together these optimizations deliver on average over 10x better performance than PostgreSQL in TPC-H queries on the same machine and even greater improvements on many common query patterns.
- Query raw data files in your data lake: Most data lakes consist of CSV/JSON/Parquet files in S3, which are passed between different systems. Now you can easily query data files and directories that are already in S3 or insert them into Iceberg tables. Query external Iceberg tables, Delta tables, and various geospatial file formats.
- Flexible data import/export: Load data directly from an S3 bucket or URL into Iceberg or regular PostgreSQL tables and write query results back to S3 to create advanced data pipelines. This Zero ETL solution allows data to flow seamlessly and in real time between systems without requiring intermediate processing.
- Seamless integrations: Crunchy Data Warehouse follows the “Lakehouse” architecture and brings together the Iceberg and PostgreSQL ecosystems. External tools can interact with Iceberg tables via PostgreSQL queries or retrieve data directly from storage.
All of this comes without sacrificing any PostgreSQL features or compatibility with the ecosystem. Crunchy Data Warehouse uses extensions to stay current with the latest version of PostgreSQL (currently 17). Additionally, you can use Crunchy Data Warehouse as both an analytical and operational database for mixed workloads by combining regular tables with Iceberg tables.
Why Apache Iceberg?
Apache Iceberg is an open format that extends from where Parquet started. With Parquet files you have an open source column-oriented file format with efficient storage and large scale data retrieval. Iceberg extends beyond Parquet offering a layer of management across sets of parquet files, changesets, and deletion files. This turns Parquet data into a database that evolves over time.
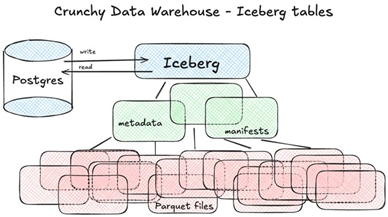
Iceberg tables are stored in a compressed columnar format for fast analytics in object storage S3 or S3 compatible such as MinIO. This means storage is cost effective and there are no storage limits. Yet the tables are still transactional and work with nearly all PostgreSQL features. Crunchy Data Warehouse can also query or load raw data from object storage into Iceberg tables via PostgreSQL commands.
A pattern we repeatedly see in data analytics scenarios is:
- Use temporary or external tables to collect raw data
- Use Iceberg as a central repository to organize data
- Use PostgreSQL tables or materialized views for querying insights
This type of 3-stage data processing is sometimes referred to as the “medallion architecture”: with bronze, raw data; silver, organized data repository; and gold, queryable insights layers. In Crunchy Data Warehouse, you can achieve in one system by composing PostgreSQL features.
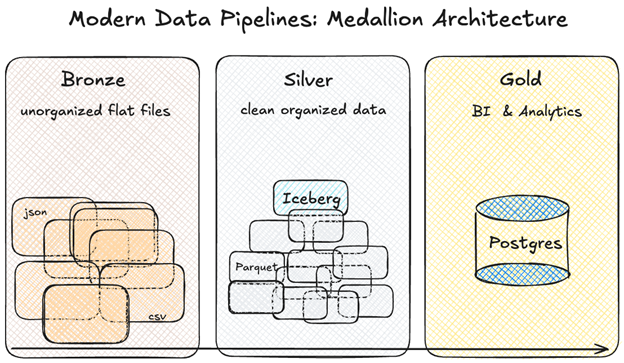
Crunchy Data Warehouse in Action – Analyzing Shipping Data in Postgres
Let’s walk through an end-to-end example of Iceberg and Postgres.
Start by creating an Iceberg table and loading raw data for AIS data. AIS is a radio protocol which ships often to share their identity, location, size, heading, and activity with each other. The NOAA Office for Coastal Management publishes a large amount of AIS data for US coastal waters.
The AIS data is published in CSV format in a .zip archive per day. For January 1st, the CSV is named AIS_2024_01_01.csv and Iceberg tables can be created directly from the data URL. With a function you can insert files every day and keep track of which files were already loaded.

With all of 2024’s data loaded into Iceberg, we can start running fast analytical queries from Postgres.
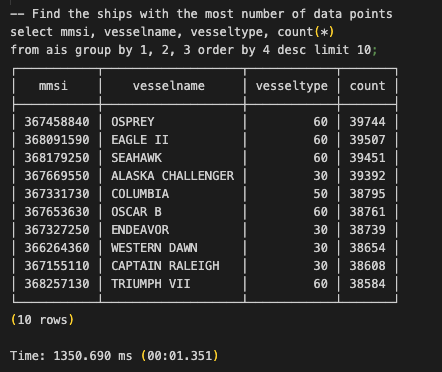
Queries on Iceberg tables are accelerated through caching and parallel, vectorized execution, and will typically run 10-100x faster than on a regular PostgreSQL table.
We can easily add query results as a layer in QGIS to make an interactive visualization. QGIS may send many queries to the database, but they will hit an indexed view.
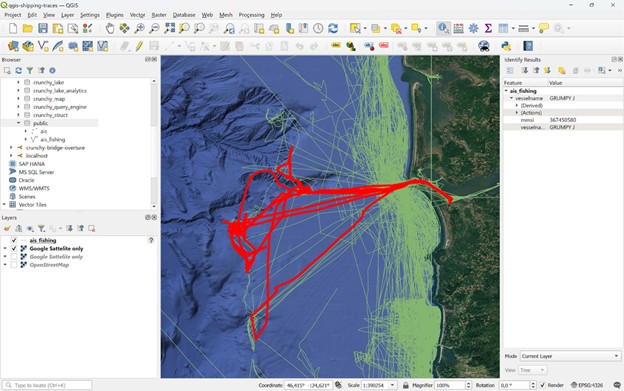
If we want other insights or visualizations, we can simply create materialized views or run queries on Iceberg directly. We can also schedule periodic refresh of the views in the database to respond to new data.
Shipping faster with Crunchy Data Warehouse
PostgreSQL features like stored procedures and extensions like PostGIS and pg_cron compose seamlessly with the analytics capabilities. PostgreSQL, with the added abilities of Crunchy Data Warehouse, can now be a powerful hub in your overall data architecture. The transactional capabilities make data processing scenarios a lot simpler and more reliable.
About IC Insiders
IC Insiders is a special sponsored feature that provides deep-dive analysis, interviews with IC leaders, perspective from industry experts, and more. Learn how your company can become an IC Insider.



