



Protecting Data in Large Language Models: How to Get Started

From IC Insider Thales Trusted Cyber Technologies
By Gina Scinta, Deputy CTO, Thales Trusted Cyber Technologies
As artificial intelligence and machine learning continue to extend into all aspects of the enterprise, there is a growing need to protect sensitive private data in Large Language Models (LLMs). This is true not only for data at rest and in transit, but also during computational execution.
The primary emphasis in protecting LLMs is the backend framework, which stores all data queried by users to the LLM, along with user credentials, logs, metadata, and more. Any prompt or response that is used and stored can contain sensitive data that requires protection.
To understand how LLM data protection works in two separate but closely related use cases, we should begin by breaking down the components of a typical LLM framework.
Understanding LLM Frameworks, RAG and RAGDB
A key component in using any LLM is its LLM framework or runtime. An LLM framework is a platform or tool focused on simplifying the deployment and use of LLMs. The goal is to provide a user-friendly interface and infrastructure for the integration of advanced AI capabilities into various applications.
Key features to look for in an LLM framework typically include ease of use, scalability and integration. The framework should simplify the interaction with LLMs through intuitive interfaces or APIs. It should also ensure that the platform can handle large-scale deployments and heavy computational load while supporting a range of models and customization options for different use cases. And it should do all this with seamless integration to existing tools and workflows, which will enhance productivity and efficiency.
Two main aspects of LLMs are Retrieval-Augmented Generation (RAG) and the RAG Database (RAGDB).
Retrieval-augmented generation (RAG) is an AI technique combining information retrieval systems with large language models (LLMs). RAG improves the accuracy and relevance of LLM output by providing access to authoritative knowledge bases.
This approach works by retrieving data relevant to a user’s query, then providing the retrieved data as context for the LLM, which uses the data to generate a response.
There are numerous benefits to this approach in terms of accuracy, relevance, cost-effectiveness and control. RAG provides access to the most current and reliable facts, which are most relevant to a user’s query. This translates to cost-effectiveness because RAG improves LLM output without retraining the model, while giving users control over the data from which responses are generated.
RAGDB (Retrieval-Augmented Generation with Databases) is an extension of the RAG framework, integrating structured databases into the retrieval-augmented generation process. This approach improves the production of accurate and contextually relevant text by utilizing structured and often more precise information from databases.
RAGDB employs structured retrieval – that is, in addition to unstructured text, RAGDB retrieves data from structured databases. This involves querying relational databases, knowledge graphs, or other structured data sources to find specific information.
Figure 1, below, depicts a typical architecture for custom-built LLMs:
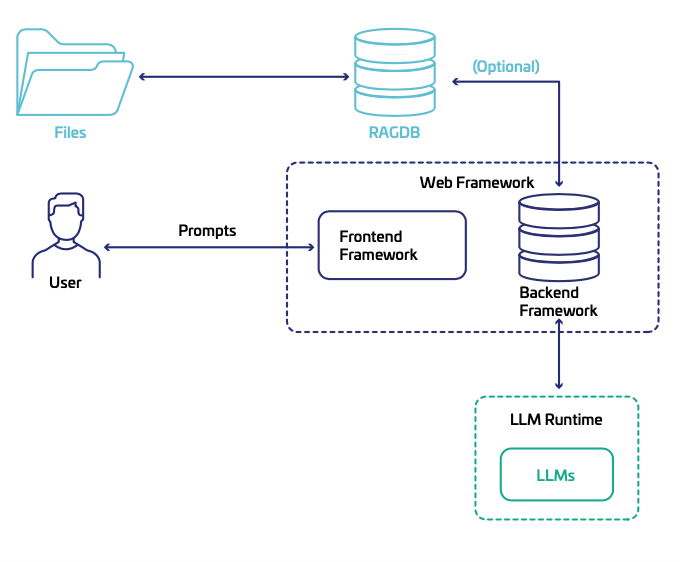
Here, the RAGDB (with the files) is an optional component, depending how the RAG capabilities are being used. The knowledge base, in the form of files and documents, is retrieved by the RAGDB.
The web framework – specifically the backend of the web framework – refers to the software structure and tools for developing the interface and logic that users interact with. These are open platforms or libraries for operating large language models (LLMs) in production.
A web framework usually handles communication between all the components. Depending on the specific framework, the backend framework (within the web framework) might also function as a separate, independent component dedicated solely to interacting with all other components, including the web framework itself.
The LLM runtime will also communicate via its APIs with the backend framework. The user will interact with the front-end framework where the UI will display the conversation (between the user and the LLMs).
Security Considerations
Ensuring data safety in LLM use cases with RAGDB requires careful security considerations. While RAG enhances query understanding and information retrieval, it also poses challenges for maintaining data privacy and security. Enhanced querying runs the risks of exposing sensitive data if it is not properly secured. Better information retrieval capabilities demand robust access controls and encryption to prevent unintended data access.
By addressing these risks and implementing the proposed solution, organizations can effectively fortify their data protection strategies and mitigate the risks associated with LLM use cases, thereby ensuring the confidentiality and integrity of sensitive information.
As noted at the outset of this commentary, securing data in LLMs has two use cases: Data protection at rest and in transit, and data protection at rest, in transit and in execution. Here are key factors to consider for each.
Data protection at rest and in transit: The need for data-centric security platforms
Data protection at rest and in transit requires a data-centric security platform to reduce risk across your organization and to decrease the number of resources required to maintain strong data security. A security platform like that described here integrates centralized data security and management core functions, such as key management, data discovery and classification, data protection and granular access controls.
By centralizing and simplifying data security, this type of platform provides efficient, integrated and fast data protection, centrally managed by the customer. This helps accelerate the time to compliance and safe cloud migrations of sensitive data.
IT teams generally favor data-centric solutions that secure data moving from networks to applications and the cloud. When perimeter network controls and endpoint security measures fail, data-centric solutions enable organizations to remain compliant with evolving privacy regulations and the demand to support a tremendous number of remote employees. Such platforms can be deployed on premises, in cloud or hybrid environments.
A data-centric security platform requires a central management component to simplify key lifecycle management tasks for all encryption keys. This should include management of secure key generation, backup/restore, clustering, deactivation, deletion, and access to partner integrations that support a variety of use cases (data discovery, data-at-rest encryption, enterprise key management, cloud key management, etc.).
Such central management should support access control to keys and policies, robust auditing, and reporting, in both physical and virtual form factors.
Protection of data at rest, in transit, and during execution: The need for end-to-end protection
Protection of data at rest, in transit and in use is a cloud infrastructure issue requiring end-to-end data security. This type of protection scenario should be centrally managed across a variety of cloud service providers.
As a concept, end-to-end protection is based on the principle of separation of duties. The customer remains in control of their own data protection for cloud deployments, and defines the profile of the cloud hardware/software stack where workloads will be computed. This approach enhances trust in cloud deployments by holding each stakeholder responsible for their respective roles and reduces the ability for a malicious actor to access code and data at rest, in transit and while being executed.
With this approach, customers can migrate existing workloads with sensitive data or create new workloads needing zero trust, confidential computing, and confidential AI to broaden data security, attestation and set the right authorizations.
With end-to-end data protection, multiple parties can securely collaborate on various use cases, such as Confidential AI datasets and models as needed while preserving privacy, confidentiality, and compliance with privacy regulations.
Protecting data at rest, in transit and in use also extends to the concepts of Confidential Virtual Machines (CVMs), third party attestation Service, and root of trust during CPU and GPU Inference.
CVMs are designed to ensure the confidentiality and integrity of data and applications while they are in use. This is particularly important in cloud computing environments where multiple tenants might share the same physical hardware.
Traditionally, data has been protected at rest and in transit, but with confidential computing technologies, this protection is extended to data in use. Confidential VMs use hardware-based encryption to protect the data in memory. Even if an attacker gains access to the physical server, they cannot read the data stored in the VM’s memory.
CVMs also ensure that the code running in the VM has not been tampered with, by verifying the integrity of the software stack, including the operating system and applications. By ensuring data confidentiality and integrity, CVMs help organizations comply with regulatory requirements for data protection.
It’s important to know the difference in the root of trust for a CPU and a GPU when used in an end-to-end solution, because there are particular hardware dependencies in each case. For example, if CPUs are used for the LLM inference, then the CPU inference runs within the confidential VM and thus it is within the root of trust a hardware-based trusted execution environment. If GPUs are used for the LLM inference, then the GPU inference runs within the runtime memory of the GPU, which is not part of that chain of trust, and requires its own attestation and verification.
Conclusion
In today’s data-driven landscape, safeguarding sensitive information in LLM use cases is vitally important.
Whether your organization is leveraging the advanced capabilities of Retrieval-Augmented Generation (RAG) or not, in addition to state-of-the-art data protection, you need a robust data-centric solution framework to protect private data in different scenarios as needed by the use case.
The threat posed to data privacy and security in LLMs demands enhanced protection for query understanding, information retrieval, and contextual responses. By implementing stringent data protection strategies, such as robust access controls and transparent encryption, organizations can mitigate the risks associated with LLM use cases.
Ultimately, end-to-end data protection may be the best solution for data protection at rest, in transit and during execution, guaranteeing the confidentiality and integrity of sensitive information. This will strengthen an organization’s data protection strategies in our current era of exponential data growth.
About Thales TCT
Thales Trusted Cyber Technologies, a business area of Thales Defense & Security, Inc., protects the most vital data from the core to the cloud to the field. We serve as a trusted, U.S. based source for cyber security solutions for the U.S. Federal Government. Our solutions enable agencies to deploy a holistic data protection ecosystem where data and cryptographic keys are secured and managed, and access and distribution are controlled.
For more information, visit www.thalestct.com
About IC Insiders
IC Insiders is a special sponsored feature that provides deep-dive analysis, interviews with IC leaders, perspective from industry experts, and more. Learn how your company can become an IC Insider.



